Распознавание речи. Обработка текстов на естественном языке.
Расширенный курс обработки естественного языка.
Авторы:
Марк Стидман, Филипп Коэн.
Лекция 1. Введение: Морфология и машины с конечными
состояниями.
Цитаты:
«Должно быть понято, что понятие «вероятность предложения» совершенно бесполезно в любых известных интерпретациях этого термина». Ноэм Хомски, 1969 год.
«Каждый раз, когда я стреляю в лингвиста, производительность нашей системы улучшается». Фредерик Желинек, 1988 год.
Кофликты?
Ученый против и инженера, объяснение языка против построения приложений, рационализм против эмпиризма, откровение против анализа данных.
В чем сложность языка?
Омонимия на многих уровнях. Есть правила, но много исключений. Нет ясного понимания, как люди обрабатывают язык.
Слова.
Определение: строки букв, разделенные пробелами.
Но как быть с:
- пунктуацией: двоеточия, многоточия и прочие типичные разделители (выделение единиц)
- дефисы: веб-сайт
- слияния слов (клитики)
- составные слова: энергонезависимый
И как быть, если нет пробелов – как в китайских иероглифах?
Подсчет слов.
Наиболее часто употребляемые слова в английском корпусе Европарламента
Все слова Существительные
|
Частота в тексте |
Единица |
|
Частота в тексте |
Слово |
|
1929379 |
the |
129851 |
European |
|
|
1297736 |
, |
110072 |
Mr |
|
|
959902 |
. |
98073 |
commision |
|
|
901174 |
of |
71111 |
president |
|
|
841661 |
to |
67518 |
parliament |
|
|
684869 |
and |
64620 |
union |
|
|
582592 |
in |
58506 |
report |
|
|
452491 |
that |
57490 |
council |
|
|
424895 |
is |
54079 |
states |
|
|
424552 |
a |
49965 |
member |
Есть большое количество слов, появляющихся только однажды. 33447 слов, появляются однажды, например cornflakes, mathematicians,Tazhikhistan.
Закон Зипфа.
f х r = k
f – частота слова, r – ранг слова (если они отсортированы по частоте), k – константа.
Сколько есть разных слов?
10000 предложений из корпуса Еврпарламента
|
Язык |
Различных слов |
|
английский |
16 тысяч |
|
французский |
22 тысячи |
|
голландский |
24 тысячи |
|
итальянский |
25 тысяч |
|
португальский |
26 тысяч |
|
испанский |
26 тысяч |
|
датский |
29 тысяч |
|
шведский |
30 тысяч |
|
немецкий |
32 тысячи |
|
греческий |
33 тысячи |
|
финский |
55 тысяч |
Почему возникают различия? Из-за морфологии.
Морфемы: основы и аффиксы.
Есть 2 типа морфем – основы и аффиксы. Есть 4 типа аффиксов
- суффикс: small+er,
cat+s, walk+ed
- префикс:un+friendly, dis+interested
- инфикс: abso+bloody+lutely,
unbe+fucking+lievable
- циркумфикс:
ge+sag+t (немецкий)
Не так все просто…
Словоизменение, нетипичные формы слов
Инфлективная морфология.
В английском:
- окончания существительных изменяются в зависимости от числа (множественное: +s) и притяжательного падежа (+’s)
- окончания глаголов изменяются в зависимости от времени (+ed, +ing) и нахождения в третьем лице единственного числа в настоящем времени (+s)
- окончания
прилагательных изменяются в сравнительной (+er) и превосходной форме (+est).
- артикли не изменяются.
В немецком:
- окончания существительных изменяются в зависимости от числа и падежа
- окончания глаголов изменяются в зависимости от времени, лица и числа
- окончания прилагательных изменяются в зависимости от числа, падежа, рода и неопределенности
- окончания артиклей изменяются в зависимости от числа, падежа и рода
Формы для английского the в немецком
|
Падеж |
Ед. число |
Мн. число |
||||
|
|
муж. род |
жен. род |
сред. род |
муж. род |
жен. род |
сред. род |
|
Именительный (субъект) |
der |
die |
das |
die |
die |
die |
|
Родительные (принадлежность) |
des |
der |
des |
der |
der |
der |
|
Дательный (непрямой объект) |
dem |
der |
dem |
den |
den |
den |
|
Винительный (прямой объект) |
den |
die |
das |
die |
die |
die |
Зачем такая сложная морфология?
- Изменение по падежам определяет роли именной фразы -> более гибкий порядок слов
- Род позволяет немного лучше передавать различия между объектами
- Но: это путь навстречу более простой морфологии
Деривационная морфология.
Использование аффиксов для порождения новых слов, зачастую других частей речи.
Пример:
- существительное: нация
- прилагательное: национальный
- наречие: национально
- глагол: национализировать
- существительное: национальность
- существительное: национализм
- существительное: национализация
Моделирование морфологии при помощи машин с конечными
состояниями.

Базовая машина с конечными состояниями:
● Начальное состояние
● Переход, соответствующий слову walk
● Конечное состояние

Два перехода и промежуточное состояние
● первый переход соответствует слову walk
● второй переход соответствует слову +ed
à walked
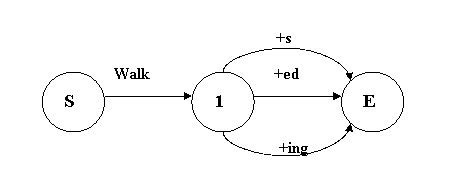
Множественные переходы между состояниями
● Три разных пути
à walks,
walked, walking
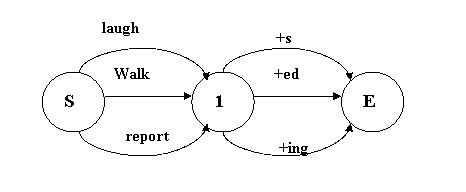
Множество основ
● обработка морфологии регулярных глаголов
● как вы можете произвести базовую форму?
● что делать с изменением окончаний, когда чередуются буквы?
● что делать с нерегулярными формами?
Лекция 6. Естественный язык и иерархия
Хомского.
Шеннон и Уивер, 1949 год.
В 1949 году Шеннон и Уивер опубликовали «Математическую теорию коммуникации», показав, что статистические аппроксимации для английского языка, основанные на Марковских процессах, могут быть использованы для его кодирования и передачи в условиях помех. Задачи вроде машинного перевода могли бы быть аппроксимированы, например, принятием русского языка как «зашумленного канала» кодированного английского.
«Когда я смотрю на статью на русском языке, я говорю: это в действительности написано на английском, но закодировано какими-то странными символами. Теперь я буду их раскодировывать.»
Аппроксимация Маркова третьего порядка для вероятностей английских письменных переходов:
-IN NO IST LAT WHEY CRATICT FROURE BIRS GROCID
PONDENOME OF DOMONSTRURES OF THE REPTAGIN IS REGOACTION OF CRE
Аппроксимация Маркова второго порядка для вероятностей английских письменных переходов:
-THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH
WRITER THAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHER METHOD FOR THE
LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED.
Хомский, 1957 год.
В 1957 году Хомский опубликовал «Синтаксические структуры», показав, что естественные грамматики не могли быть точно переданы такими методами. Было похоже на то, что машинный перевод не мог быть смоделирован как зашумленный канал (хотя машины были слишком слабыми, чтобы в действительности это проверить).
Хомский явно оставил открытой идею, что статистика могла руководить обработкой грамматики.
«Имея грамматику языка, кто-то может учиться использовать язык статистически разными способами; и разработка вероятностных моделей использования языка ( отдельно от синтаксической структуры языка) может быть довольно многообещающей»
Хомский, 1957:17, запись 4.
Не смотря на это, большинство работ в компьютерной лингвистике переключилось на лингвистически образованные представления синтаксиса и семантики и небольшие области знаний (например, проект LUNAR 1970-х годов).
Возвращение статистических моделей.
Около 1988 машины стали достаточно мощными, чтобы попробовать обе технологии в реальном масштабе. К всеобщему сюрпризу, низкоуровневые аппроксимации, такие как Марковские процессы, работали лучше, чем построенные вручную лингвистически образованные представления почти на всех задачах, таких как распознавание речи, разбор свободного текста, и, в конечном итоге, машинном переводе как таковом.
Причины были двоякими:
-Область исследований для систем разбора в грамматиках с реальными размерами данных достаточно велика, что приводит к синтаксической омонимии (неоднозначности), требующей статистических моделей.
-Все в естественном языке подчиняется закону степенного распределения, также известному как закон Зипфа.
На что должна быть похожа система разбора.
“In a generally way such speculation is
epistemologiccaly relevant? A suggesting how organism naturing and evolving in
physical environment we know might conceivably end up discoursing of abstract
objects as we do”
(«В общем случае эпистемологически подходящим является предположение, что подобно тому как организмы вызревают и плодоносят в физической среде, наши знания могут положить конец дискуссиям об абстрактных объектах, которой мы до сих пор занимаемся») (Куин 1960:123б из Эбни 1996 год).
objects as we do
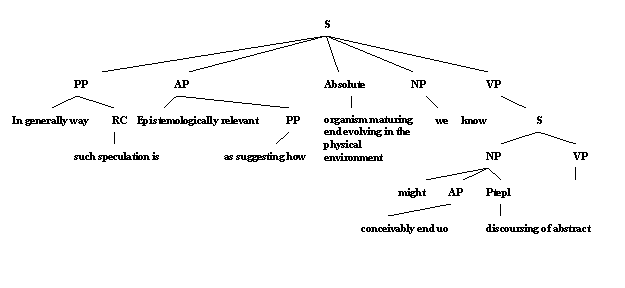
Парадокс Зипфа.
Из закон Зипфа следует , что можно получить 80% диапазона, моделируя наиболее часто встречающиеся события, и игнорируя длинный «хвост» все остальных экспоненциально более редких событий. Однако закон Зипфа также означает, что вся информация о системе находится в длинном «хвосте» экспоненциально более редких событий. Машинное обучение проходит очень плохо в системах, где вся информация находится в редких событиях.
Настоящее.
Большинство работ в компьютерной лингвистике переключилось на не лингвистически образованные низкоуровневые статистические аппроксимации и машинное обучение. Однако, около 2000 года, снова начался процесс объединения лингвистических, статистических моделей и машинного обучения. Когда был обнародован закон Мура, стало ясно, что такое объединение – основа дальнейшего развития компьютерной лингвистики.
Знание законов языка и производительности.
Первые три главы работы Хомского 1957 года показали, что человеческие языки находятся ниже уровня языков с конечными состояниями, по крайней мере на уровне контекстно-свободных языков.
Доказательство требует разграничения идеального лингвистического пространства, называемого сейчас языковой компетенцией (знанием законов языка), и механизма производительности, с которой на самом деле обрабатываются предложения.
Языковая компетенция допускает предложения столь длинные и развернутые, что ни у кого из нас нет времени и достаточной памяти, чтобы их обработать. Но их не позволяют требования производительности. Впрочем, для обработки реального языка это и не нужно.
Сложность человеческого языка.
«Синтаксические структуры» утверждают, что уровень человеческих языков еще выше. Статья поднимает вопрос (но не отвечает на него), какой уровень достаточно высок, чтобы вместить в себя все человеческие языки.
Когда мы подходим к проблеме разбора с объемами, сравнимыми с теми, которые обрабатывает читатель текстов типа книг и газет – к вопросу производительности в терминах Хомского, - мы находим, что вероятностная модель, предложенная Хомским в 1948 году поистине великолепна.
Расширенная иерархия Хомского.
|
Тип грамматик
(языков) |
Автомат |
Тип правил |
Пример |
|
0: регулярные |
Универсальная машина
Тьюринга |
α à β |
|
|
1: контекстно-зависимые |
Автомат линейных связей |
φAψàφαψ |
ар |
|
индексированные |
Вложенный стековый автомат |
A[(i),…]àφB[(i),…]ψC[(i),…]Χ |
а2
, а4 ,
а8 и т. д. |
|
LCFR |
Вложенный PDA i-го порядка |
A à f(φ) |
anbncndn…mn |
|
LI |
Вложенный PDA |
A[(i),…]àφB[(i),…]ψ |
anbncn |
|
2: контекстно-свободные |
Стековый автомат (PDA) |
A à α |
anbn |
|
3: конечных состояний |
Автомат с конечными
состояниями |
A à aB A à a |
an |
Здесь a, b и т.д. – терминальные, то есть атомные символы языка (обычно – слова).
A, B и т.д. – нетерминальные символы, то есть типы фраз языка
(например, именная NP
или глагольная VP).
α, β и т.д. – любые строки терминальных и нетерминальных символов, включая пустую строку.
аn – строка из повторяющихся n символов а.
Характеристики языков, автоматов и грамматик любого уровня
иерархии относятся к нижележащим уровням в том смысле, что множество языков на
этом уровне правильно включает множество языков нижележащих уровней, а автомат
может симулировать действие автоматов нижележащих уровней, и множество
возможных типов правил правильно включает типы правил нижележащих уровней.
Сказанное не относится к уровням индексированных грамматик и LCFRS, которые являются скорее перекрывающими, а не включающими.
Грамматики, языки и деревья.
Грамматика определяется как множество T терминальных символов, множество N нетерминальных символов, множество правил R, начальный символ S, взятый из N.
Так определенная грамматика «порождает» язык, определяемый как (обычно бесконечное) множество строк терминалов, которые можно получить начав с начального символа и применяя все возможные правила, а затем применяя все возможные правила к нетерминальным символам в полученных строках, и так далее.
Для любой данной строки в языке эта процедура привлекает одно или более «порождений» (дериваций) или последовательностей применения правил, обычно представляемых в виде деревьев. Деревья сильно связаны с процессом семантической интерпретации.
Тип 2. Контекстно-свободные языки.
Существуют свойства языка, которые не могут быть полностью переданы посредством автоматов с конечными состояниями или Марковскими процессами любого порядка. Нет автомата с конечными состояниями, который мог бы сгенерировать язык anbn – строки, содержащие одну или более a, за которыми идет то же количество b.
Добавление счетчика к такому автомату сделает его автоматом не с конечными состояниями.
Нам нужен новый тип машины, называемый стековый автоматом (PDA). PDA - это автомат с конечными состояниями, к которому добавлен участок памяти с доступом «последним пришел – первым вышел», то есть стек. Переходы могут не только порождать или поглощать символ, но также заталкивать элементы на верх стека или выталкивать их с вершины стека. Следующий автомат порождает anbn , где n не меньше 1, принимая общее условие, что стек должен быть пуст после завершения:
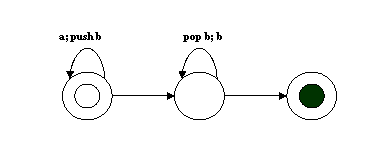
Этому автомату соответствует контекстно-свободные грамматика S à a S b и S à ab, а так выглядит дерево для строки aaabbb:
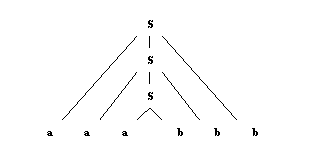
Заметим, что зависимости между парами a и b для каждого успешного применения правила, являются вложенными.
Тип 2. Вероятностные контекстно-свободные грамматики.
Если мы присоединим понятие вероятности к продукциям контекстно-свободной грамматики, мы получим вероятностную контекстно-свободную грамматику (PCFG).
Так интерпретируемые PCFG дают на удивление плохие приближение для английского и других языков, так как предположения о независимости, которые они воплощают (так как способ, которым строятся дочерние по отношению к глагольной фразе VP именные фразы NP, независимы от того как строится V), ошибочны.
Мы посмотрим, как это обойти, когда рассмотрим вероятностный
разбор.
Сильная и слабая эквивалентность.
Про две грамматики говорят, что они слабо эквивалентны, если они порождают одинаковые языки или множества строк.
Две грамматики сильно эквивалентны, если им соответствуют одинаковые деревья для каждой строки в одном и том же языке.
Все грамматики на данном уровне иерархии имеют сильно эквивалентные грамматики на более высоких уровнях, но не наоборот.
Сильная и слабая адекватность.
О грамматике или классе грамматик говорят, что они строго адекватны языку или классу языков, если они сопоставляют правильные деревья строкам.
Слабо эквивалентные грамматики, которые сопоставляют неправильные деревья являются слабо адекватными.
Выразительная мощность естественных грамматик.
Хомский утверждал на основании свойств рекурсивности и внедряемости естественных языков, что сильная адекватность требует для естественных грамматик как минимум контекстно-свободной мощности.
Следующее семейство предложений в английском языке обладает свойством встраивания простых предложений внутрь предложений на неограниченную глубину, что показано квадратными скобками:
И так далее…
О периферийной рекурсии.
Однако, правильное периферийное встраивание может быть передано регулярной грамматикой, следовательно является в слабом смысле относящимся к грамматикам конечных состояний.
Заметим, что для целей семантики нам нужна рекурсия, то есть как лингвисты мы думаем об этом явлении, как об относящемся к контекстно-свободным грамматикам.
То, что явление является в слабом смысле относящимся к грамматикам конечных состояний, означает, что существует итеративный путь передачи семантики, как в хвостовой рекурсии языков программирования.
Как минимум контекстно-свободная мощность.
Решающим, фактически, является явление центрального встраивания, для которого нет даже слабо адекватной грамматики конечных состояний. Так, лучший пример относится к немецкому языку:
that
I Henry swim saw
“that I saw Henry
swim”
«что я видел, что Андрей плывет»
that
I John Henry swim see saw
“that I saw John see
Henry swim”
«что я видел, что Иван видит, что Андрей плывет»
that
I Anna
John Henry swim see help
saw
“that I saw Anna help
John see Henry swim”
«что я видел, что Анна помогает, чтобы Иван видел, что Андрей плывет»
Более, чем контекстно-свободная
мощность.
Хомский убедительно доказал, что контекстно-свободные грамматик не адекватны в сильном смысле.
Например, сильно адекватная грамматика для голландского, похоже, требует более, чем контекстно-свободной мощности:
that
I Henry
saw swim
“that I saw Henry
swim”
«что я видел, что Андрей плывет»
that
I John
Henry saw see
swim
“that I saw John see
Henry swim”
«что я видел, что Иван видит, что Андрей плывет»
that
I Anna
John Henry saw
help see swim
“that I saw Anna help
John see Henry swim”
«что я видел, что Анна помогает, чтобы Иван видел, что Андрей плывет»
Какая все-таки мощность?
Какая нам нужна мощность? Чем меньше мы будем забивать себе голову, тем лучше.
Большинство феноменов ограничено, по-видимому, контекстно-свободной мощностью.
Лекция 7. Синтаксические категории.
Три взгляда на синтаксические структуры.
- Грамматика фразовых структур
- Категориальная грамматика
- Грамматика зависимостей
Игрушечная грамматика CFPS (контекстных фразовых структур) для фрагмента
английского языка.
S à NP VP
NP à the N
NP à {John, Mary, Fred, Sally,…}
VP à TV NP
VP à CV Scomp
Scomp à that S
N à {man,woman,boy,girl,…}
TV à {see, like, loath,…}+s
CV à {see, know, dream,
…}+s
Деривация CFPS.
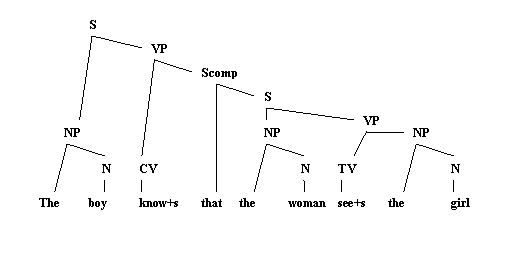
Структура древа отражает структуру интерпретации или логическую форму.